Análise. Eliminando a recursão à esquerda Removendo a recursão à esquerda
Classificação das gramáticas formais segundo Chomsky
· Gramática do tipo 0 (forma geral). As regras têm a forma α→β
· Gramática tipo 1 (dependente do contexto, KZ)
As regras têm a forma αAβ → αγβ. γ pertence a V +, ou seja, gramática não é truncada
α,β são chamados contexto esquerdo e direito
· Gramática tipo 2 (livre de contexto, KS)
As regras são da forma A → α. α pertence a V*, ou seja, gramática pode ser encurtada => idiomas KS não estão contidos em KS
Mais próximo do BPF
· Gramática tipo 3 (automática, regular)
As regras são da forma A → aB, A → a, A → ε
Idiomas automáticos estão contidos em idiomas CS
Exemplo. Uma gramática que gera uma linguagem de expressões regulares entre parênteses.
S → (S) | SS | ε
Geração (inferência)
Designações
=>+ (1 ou mais)
=>* (0 ou mais)
Forma sentencial de gramáticaé uma string que pode ser derivada do caractere inicial.
Frase (frase) de gramáticaé uma forma sentencial que consiste apenas em terminais.
Gramática da linguagem L(G)- este é o conjunto de todas as suas propostas.
Designações:
Saída esquerda, direita (geração).
Saída esquerda e direita para frase i + i * i
A árvore de saída (árvore sintática, árvore de análise) de uma sequência de frases. Ao contrário da geração, as informações sobre a ordem de inferência são excluídas dela.
Analisar a copa da árvore - cadeia de marcas de folhas da esquerda para a direita
Uma gramática que produz mais de uma árvore de análise para alguma sentença é chamada ambíguo.
Um exemplo de gramática ambígua. Gramática das expressões aritméticas.
E → E+E | E*E | eu
Duas árvores de análise para cadeia i + i * i
Um exemplo de gramática ambígua. Gramática de declaração condicional
S → se b então S
| se b então S, senão S
Duas árvores de análise para a cadeia se b então se b então a
Converter para gramática inequívoca equivalente:
S → se b então S
| se b então S2 senão S
S2 → se b então S2 senão S2
44. Linguagens formais e gramáticas: linguagens não vazias, finitas e infinitas

45.Equivalência e minimização de autômatos
Equivalência de máquinas de estados finitos
Seja S um alfabeto (um conjunto finito de símbolos) e S* o conjunto de todas as palavras do alfabeto S. Denotemos por e uma palavra vazia, ou seja, não contém letras (símbolos de S), mas o sinal × - a operação de atribuição (concatenação) de palavras.
Então, aav × va = aavva. O sinal × da operação de atribuição é frequentemente omitido.
As palavras do alfabeto S serão denotadas por letras gregas minúsculas a, b, g, .... Obviamente, e é a unidade para a operação de atribuição:
Também é óbvio que a operação de atribuição é associativa, ou seja, (ab)g = a(bg).
Assim, o conjunto S* de todas as palavras do alfabeto S em relação à operação de atribuição é um semigrupo com identidade, ou seja, monóide;
S* é chamado de monóide livre sobre o alfabeto S.
Minimização de Máquina de Estado
Diferentes máquinas de estados podem funcionar da mesma maneira, mesmo que tenham números diferentes de estados. Uma tarefa importante é encontrar uma máquina de estados finitos mínimos que implemente um determinado mapeamento de autômato.
É natural chamar dois estados de um autômato de equivalentes, que não podem ser distinguidos por nenhuma palavra de entrada.
Definição 1: Dois estados p e q de uma máquina de estados finitos
A = (S,X,Y,s0,d,l) são chamados de equivalentes (denotados por p~q) se ("aО X*)l*(p,a) =l*(q, a)
46. Equivalência de máquinas de Turing de fita única e multi-fita
É óbvio que o conceito de uma MT de fita k é mais amplo do que o conceito de uma máquina “normal” de fita única. DEFINIÇÃO 6. A máquina de fita (k+1) M′ com programa w simula a máquina de fita k M se para qualquer conjunto de palavras de entrada (x1, x2,…, xk) o resultado do trabalho M′ coincide com o resultado do trabalho M nos mesmos dados de entrada. Supõe-se que a palavra w é escrita primeiro na (k+1)-ésima fita M′. O resultado é entendido como o estado das primeiras k fitas MT no momento da parada, e se M não parar em uma determinada entrada, então a máquina que a simula também não deve parar nesta entrada.
DEFINIÇÃO 7. Um MT M* de fita (k+1) é chamado de máquina de Turing universal para máquinas de fita k se para qualquer máquina de fita k M houver um programa w no qual M* simula M. 12 Observe: em Para a definição de um MT universal, a mesma máquina M′ deve simular diferentes máquinas de fita k (em diferentes programas w). Considere o seguinte teorema. TEOREMA 3. Para qualquer k≥1, existe uma máquina de fita universal (k+1)–Turing. Prova. Vamos provar o teorema construtivamente, ou seja, Vamos mostrar como se pode construir a máquina universal necessária M*. Consideremos apenas o esquema geral de construção, omitindo detalhes complexos. A ideia principal é colocar uma descrição da máquina de Turing simulada em uma (k+1)-ésima fita adicional e usar esta descrição durante o processo de simulação.
DEFINIÇÃO 8. Diremos que uma máquina de Turing M calcula uma função parcial f:A*→A* se para qualquer x∈A* escrito na primeira fita da máquina M: se f(x) for definido, então M para , e no momento da parada, a palavra f(x) está escrita na última fita da máquina; se f(x) não estiver definido, então a máquina M não para.
DEFINIÇÃO 9. Diremos que as máquinas M e M′ são equivalentes se calcularem a mesma função. O conceito de equivalência é “mais fraco” que o de simulação: se uma máquina M′ simula uma máquina M, então a máquina M′ é equivalente a M; o inverso, em geral, não é verdadeiro. Por outro lado, a simulação exige que M′ tenha pelo menos tantas fitas quanto M, enquanto a equivalência não exige 15. É esta propriedade que nos permite formular e provar o seguinte teorema.
TEOREMA 4. Para qualquer máquina de fita k M com complexidade de tempo T(n), existe uma máquina de fita única equivalente M′ com complexidade de tempo T′ (n) = O(T 2 (n)).
48. Transformações equivalentes de gramáticas KS: exclusão de regras de cadeia, remoção de uma regra gramatical arbitrária
Definição. Regra gramatical gentil , Onde , V A é chamado corrente.
Declaração. Para uma gramática KS Γ contendo regras em cadeia, é possível construir uma gramática equivalente Γ" que não contenha regras em cadeia.
A ideia da prova é a seguinte. Se o esquema gramatical tiver a forma
R = (..., ,...,
então tal gramática é equivalente a uma gramática com um esquema
R" = (..., a
já que a saída na gramática com o diagrama de circuito R da cadeia a
pode ser obtido em uma gramática com o esquema R" usando a regra a
Em geral, a prova da última afirmação pode ser feita da seguinte forma. Vamos dividir R em dois subconjuntos R 1 e R 2, incluindo em R 1 todas as regras da forma
Para cada regra de R 1 encontramos um conjunto de regras S( ), que são construídos assim:
Se *e em R 2 existe uma regra α, onde α é a cadeia do dicionário (V t V A)*, então em S( ) ativar a regra
Vamos construir um novo esquema R" combinando as regras R 2 e todos os conjuntos construídos S( ). Obtemos uma gramática "G" = (V t, VA , I, R"), que é equivalente à dada e não contém regras da forma .
Como exemplo, vamos realizar a exceção das regras da cadeia da gramática de G 1.9 com o esquema:
R=(
Primeiro, vamos dividir as regras gramaticais em dois subconjuntos:
R1 = (
R2 = (
Para cada regra de R 1 construímos um subconjunto correspondente.
S(
S(
Como resultado, obtemos o esquema gramatical desejado sem regras de cadeia na forma:
R2U S(
O último tipo de transformação em consideração está associado à remoção de regras com o lado direito vazio da gramática.
Definição. Regra gentil $ é chamado regra anulatória.
49.Transformações equivalentes de gramáticas KS: remoção de símbolos inúteis.
Seja dada uma gramática KS arbitrária G . Não terminal A esta gramática é chamada produtivo , se houver uma cadeia terminal (incluindo uma vazia) tal que A Þ * a improdutivo.
Teorema. Toda gramática CS é equivalente a uma gramática CS sem não-terminais improdutivos.
Não terminal A gramática G chamado alcançável , se tal cadeia existir a , O que S Þ * a . Caso contrário, o não-terminal é chamado inatingível.
Teorema. Cada gramática KS é equivalente a uma gramática KS sem não-terminais inacessíveis.
Um símbolo não terminal em uma gramática KS é chamado inútil (ou redundante) , se for inatingível ou improdutivo.
Teorema. Toda gramática CS é equivalente a uma gramática CS na qual não existem não-terminais inúteis.
Exemplo. Elimine símbolos inúteis na gramática
S® aC | A; A ® táxi; B ® b; C ® a.
Passo 1. Estamos construindo muito alcançável personagens: {S} ® { S, C, A}® { S, C, A, B}. Todos os não-terminais são acessíveis. Não existem inatingíveis, a gramática não muda.
Passo 2. Estamos construindo muito produtivo personagens: {C,B}® { S, C, B}. Nós entendemos isso A - não produtivo. Nós eliminamos isso e todas as regras da gramática. Nós temos
S® aC; B ® b; C ® a.
etapa 3. Estamos construindo muito alcançável símbolos da nova gramática: {S} ® { S, C}. Nós entendemos isso B inatingível. Nós eliminamos isso e todas as regras da gramática. Nós temos
S® aC; C ® a.
Esse é o resultado final.
50. Transformações equivalentes de gramáticas KS: eliminação da recursão à esquerda, fatoração à esquerda
Removendo a recursão à esquerda
A principal dificuldade ao usar a análise preditiva é encontrar uma gramática para a linguagem de entrada que possa ser usada para construir uma tabela de análise com entradas definidas exclusivamente. Às vezes, com algumas transformações simples, uma gramática não-LL(1) pode ser reduzida a uma gramática LL(1) equivalente. Dentre essas transformações, as mais eficazes são a fatoração à esquerda e a remoção recursão à esquerda. Dois pontos precisam ser feitos aqui. Em primeiro lugar, nem toda gramática se torna LL(1) após estas transformações e, em segundo lugar, após tais transformações a gramática resultante pode tornar-se menos compreensível.
A recursão direta à esquerda, ou seja, a recursão do formulário, pode ser removida da seguinte maneira. Primeiro agrupamos as regras A:
onde nenhuma das strings começa com A. Então substituímos este conjunto de regras por
![]()
onde A" é um novo não-terminal. Do não-terminal A você pode derivar as mesmas cadeias de antes, mas agora não pode recursão à esquerda. Este procedimento remove todos os recursões à esquerda, mas a recursão à esquerda envolvendo duas ou mais etapas não é removida. Dado abaixo algoritmo 4.8 permite que você exclua tudo recursões à esquerda da gramática.
Fatoração à esquerda
A ideia principal da fatoração à esquerda é que, no caso em que não está claro qual das duas alternativas deve ser usada para expandir um A não terminal, é necessário alterar as regras A de modo a adiar a decisão até que haja informação suficiente para tomar a decisão correta.
Se ![]() - duas regras A e a cadeia de entrada começa com uma string não vazia, a saída de não sabemos se deve ser expandida de acordo com a primeira regra ou a segunda. Você pode adiar a decisão expandindo . Então, depois de analisar o que é dedutível, você pode expandir por ou por . As regras fatoradas à esquerda assumem a forma
- duas regras A e a cadeia de entrada começa com uma string não vazia, a saída de não sabemos se deve ser expandida de acordo com a primeira regra ou a segunda. Você pode adiar a decisão expandindo . Então, depois de analisar o que é dedutível, você pode expandir por ou por . As regras fatoradas à esquerda assumem a forma
![]()
51. Linguagem de máquina de Turing.
A máquina de Turing inclui um ilimitado em ambas as direções fita(São possíveis máquinas de Turing que possuem várias fitas infinitas), divididas em células, e dispositivo de controle(também chamado cabeça de leitura e escrita (GZCH)), capaz de estar em um dos conjunto de estados. O número de estados possíveis do dispositivo de controle é finito e especificado com precisão.
O dispositivo de controle pode mover-se para a esquerda e para a direita ao longo da fita, ler e escrever caracteres de algum alfabeto finito nas células. Destaca-se especial vazio um símbolo que preenche todas as células da fita, exceto aquelas (o número final) nas quais os dados de entrada estão gravados.
O dispositivo de controle opera de acordo com regras de transição, que representam o algoritmo, realizável esta máquina de Turing. Cada regra de transição instrui a máquina, dependendo do estado atual e do símbolo observado na célula atual, a escrever um novo símbolo nesta célula, passar para um novo estado e mover uma célula para a esquerda ou direita. Alguns estados da máquina de Turing podem ser rotulados como terminal, e ir para qualquer um deles significa o fim do trabalho, parando o algoritmo.
Uma máquina de Turing é chamada determinístico, se cada combinação de estado e símbolo de faixa na tabela corresponder a no máximo uma regra. Se houver um par "símbolo de fita - estado" para o qual existem 2 ou mais instruções, tal máquina de Turing é chamada não determinístico.
LL(k)-gramática se, para uma determinada string e os primeiros k caracteres (se houver) derivados de , existe no máximo uma regra que pode ser aplicada a A para obter a saída de alguma string terminal,
Arroz. 4.4.
começando e continuando com os k terminais mencionados.
Uma gramática é chamada de gramática LL(k) se for uma gramática LL(k) para algum k.
Exemplo 4.7. Considere a gramática G = ((S, A, B), (0, 1, a, b), P, S), onde P consiste em regras
S -> A | B, A -> aAb | 0, B -> aBbb | 1.
Aqui . G não é uma gramática LL (k) para qualquer k. Intuitivamente, se começarmos lendo uma sequência longa de caracteres a , não saberemos qual das regras S -> A e S -> B foi aplicada primeiro até encontrarmos 0 ou 1 .
Passando para a definição exata da gramática LL (k), definimos e y = a k 1b 2k . Então conclusões

correspondem às conclusões (1) e (2) da definição. Os primeiros k caracteres das strings x e y são iguais. No entanto, a conclusão é falsa. Como k é escolhido aqui arbitrariamente, G não é uma gramática LL.
Consequências da definição da gramática LL(k)
Teorema 4.6. Gramática KS é uma gramática LL(k) se e somente se para duas regras diferentes e da interseção P vazio com tudo isso , O que ![]() .
.
Prova. Necessidade. Suponhamos que e satisfaça as condições do teorema e contenha x . Então, pela definição de FIRST, para alguns y e z existem conclusões

(Observe que aqui aproveitamos o fato de que N não contém não-terminais inúteis, como é assumido para todas as gramáticas em consideração.) Se |x|< k ; то y = z = e . Так как , то G не LL (k)- грамматика .
Adequação. Suponhamos que G não seja uma gramática LL(k).
Então há duas conclusões
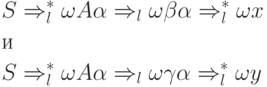
que as cadeias xey coincidem nas primeiras k posições, mas . Portanto e são regras diferentes de P e de cada um dos conjuntos ![]() E
E ![]() contém a cadeia PRIMEIRO k (x) coincidindo com a cadeia PRIMEIRO k (y).
contém a cadeia PRIMEIRO k (x) coincidindo com a cadeia PRIMEIRO k (y).
Exemplo 4.8. Uma gramática G que consiste em duas regras S -> aS | a não será uma gramática LL(1), pois
PRIMEIRO 1 (aS) = PRIMEIRO 1 (a) = a.
Intuitivamente, isso pode ser explicado da seguinte forma: vendo apenas este primeiro caractere ao analisar uma cadeia começando com o símbolo a, não sabemos qual das regras S -> aS ou S -> a deve ser aplicada a S. Por outro lado, G é uma gramática LL(2). Na verdade, na notação do teorema que acabamos de apresentar, se ![]() , então A = S e . Como apenas as duas regras indicadas são fornecidas para S, então. Como FIRST2(aS) = aa e FIRST2(a) = a, então pelo último teorema G será uma gramática LL (2).
, então A = S e . Como apenas as duas regras indicadas são fornecidas para S, então. Como FIRST2(aS) = aa e FIRST2(a) = a, então pelo último teorema G será uma gramática LL (2).
Removendo a recursão à esquerda
A principal dificuldade ao usar a análise preditiva é encontrar uma gramática para a linguagem de entrada que possa ser usada para construir uma tabela de análise com entradas definidas exclusivamente. Às vezes, com algumas transformações simples, uma gramática não-LL(1) pode ser reduzida a uma gramática LL(1) equivalente. Dentre essas transformações, as mais eficazes são a fatoração à esquerda e a remoção da recursão à esquerda. Dois pontos precisam ser feitos aqui. Em primeiro lugar, nem toda gramática se torna LL(1) após estas transformações e, em segundo lugar, após tais transformações a gramática resultante pode tornar-se menos compreensível.
A recursão direta à esquerda, ou seja, a recursão do formulário, pode ser removida da seguinte maneira. Primeiro agrupamos as regras A:
onde nenhuma das linhas começa com A . Então substituímos este conjunto de regras por

onde A" é o novo não terminal. As mesmas cadeias podem ser deduzidas do não terminal A como antes, mas agora não há recursão à esquerda. Este procedimento remove todas as recursões à esquerda imediatas, mas não remove a recursão à esquerda envolvendo duas ou mais etapas. Dado abaixo algoritmo 4.8 permite remover todas as recursões à esquerda da gramática.
Algoritmo 4.8. Removendo a recursão à esquerda.
Entrada. Gramática KS G sem regras eletrônicas (da forma A -> e ).
Saída. KS-gramática G" sem recursão à esquerda, equivalente a G.
Método. Siga as etapas 1 e 2.
(1) Organize os não-terminais da gramática G em qualquer ordem.
(2) Execute o seguinte procedimento:

Após a (i-1)-ésima iteração do loop externo na etapa 2 para qualquer regra da forma ![]() , onde k< i
, выполняется s >k. Como resultado, na próxima iteração (por i), o loop interno (por j) aumenta sucessivamente o limite inferior de m em qualquer regra
, onde k< i
, выполняется s >k. Como resultado, na próxima iteração (por i), o loop interno (por j) aumenta sucessivamente o limite inferior de m em qualquer regra ![]() , até que haja m >= i . Então, após remover a recursão imediata à esquerda para as regras A i, m torna-se maior que i.
, até que haja m >= i . Então, após remover a recursão imediata à esquerda para as regras A i, m torna-se maior que i.
A principal dificuldade ao usar a análise preditiva é encontrar uma gramática para a linguagem de entrada que possa ser usada para construir uma tabela de análise com entradas definidas exclusivamente. Às vezes, com algumas transformações simples, uma gramática não-LL(1) pode ser reduzida a uma gramática LL(1) equivalente. Dentre essas transformações, as mais eficazes são a fatoração à esquerda e a remoção recursão à esquerda. Dois pontos precisam ser feitos aqui. Em primeiro lugar, nem toda gramática se torna LL(1) após estas transformações e, em segundo lugar, após tais transformações a gramática resultante pode tornar-se menos compreensível.
A recursão direta à esquerda, ou seja, a recursão do formulário, pode ser removida da seguinte maneira. Primeiro agrupamos as regras A:
onde nenhuma das strings começa com A. Então substituímos este conjunto de regras por

onde A" é um novo não-terminal. Do não-terminal A você pode derivar as mesmas cadeias de antes, mas agora não pode recursão à esquerda. Este procedimento remove todos os recursões à esquerda, mas a recursão à esquerda envolvendo duas ou mais etapas não é removida. Dado abaixo algoritmo 4.8 permite que você exclua tudo recursões à esquerda da gramática.
Algoritmo 4.8. Remoção recursão à esquerda.
Entrada. Gramática KS G sem regras eletrônicas (da forma A -> e).
Saída. KS-gramática G" sem recursão à esquerda, equivalente a G.
Método. Siga as etapas 1 e 2.
(1) Organize os não-terminais da gramática G em qualquer ordem.
(2) Execute o seguinte procedimento:

Após a (i-1)-ésima iteração do loop externo na etapa 2 para qualquer regra da forma ![]() , onde k< i, выполняется s >k. Como resultado, na próxima iteração (por i), o loop interno (por j) aumenta sucessivamente o limite inferior de m em qualquer regra
, onde k< i, выполняется s >k. Como resultado, na próxima iteração (por i), o loop interno (por j) aumenta sucessivamente o limite inferior de m em qualquer regra ![]() , até m >= eu. Então, depois de remover o imediato recursão à esquerda para regras A i, m torna-se maior que i.
, até m >= eu. Então, depois de remover o imediato recursão à esquerda para regras A i, m torna-se maior que i.
Algoritmo 4.8 aplicável se a gramática não possuir e - regras (regras da forma A -> e). As regras eletrônicas presentes na gramática podem ser excluídas primeiro. A gramática resultante sem recursão à esquerda pode ter regras eletrônicas.
Fatoração à esquerda
A ideia principal da fatoração à esquerda é que, no caso em que não está claro qual das duas alternativas deve ser usada para expandir um A não terminal, é necessário alterar as regras A de modo a adiar a decisão até que haja informação suficiente para tomar a decisão correta.
Se ![]() - duas regras A e a cadeia de entrada começa com uma string não vazia, a saída de não sabemos se deve ser expandida de acordo com a primeira regra ou a segunda. Você pode adiar a decisão expandindo . Então, depois de analisar o que é dedutível, você pode expandir por ou por . As regras fatoradas à esquerda assumem a forma
- duas regras A e a cadeia de entrada começa com uma string não vazia, a saída de não sabemos se deve ser expandida de acordo com a primeira regra ou a segunda. Você pode adiar a decisão expandindo . Então, depois de analisar o que é dedutível, você pode expandir por ou por . As regras fatoradas à esquerda assumem a forma
![]()
Algoritmo 4.9. Fatoração à esquerda da gramática.
Entrada. KS-gramática G.
Saída. Gramática KS fatorada à esquerda G" equivalente a G.
Método. Para cada não-terminal A, encontre o prefixo mais longo comum a duas ou mais de suas alternativas. Se, isto é, houver um prefixo comum não trivial, substitua todas as regras A
onde z denota todas as alternativas que não começam com
![]()
onde A" é o novo não-terminal. Aplique esta transformação até que não haja duas alternativas com um prefixo comum.
Exemplo 4.9. Consideremos novamente a gramática das declarações condicionais de exemplo 4.6:
S -> se E então S | se E então S, senão S | uma E -> b
Após a fatoração à esquerda, a gramática assume a forma
S -> se E então SS" | a S" -> senão S | e E -> b
Infelizmente, a gramática permanece ambígua e, portanto, não é uma gramática LL(1).
A peculiaridade das gramáticas formais é que elas permitem definir um conjunto infinito de cadeias de uma linguagem usando um conjunto finito de regras (é claro, o conjunto de cadeias de uma linguagem também pode ser finito, mas mesmo para linguagens reais simples esta condição geralmente não é atendida). O exemplo de gramática para inteiros decimais com sinal acima define um conjunto infinito de inteiros usando 15 regras.
A capacidade de usar um conjunto finito de regras é alcançada nesta forma de notação gramatical por meio de regras recursivas. A recursão nas regras gramaticais se expressa no fato de um dos símbolos não terminais ser definido por si mesmo. A recursão pode ser direta (explícita) - então o símbolo é definido por si mesmo em uma regra, ou indireta (implícita) - então a mesma coisa acontece através de uma cadeia de regras.
Na gramática G discutida acima, a recursão direta está presente na regra:<чс>-»<чс><цифра>, e em sua gramática equivalente G" - na regra: T-VTF.
Para que a recursão não seja infinita, para o símbolo não terminal da gramática que dela participa também devem existir outras regras que a definam, contornando-se, e permitam evitar uma definição recursiva infinita (caso contrário, este símbolo seria simplesmente não é necessário na gramática). Estas regras são<чс>-»<цифра>- na gramática de G e T->F - na gramática de G."
Na teoria das linguagens formais nada mais pode ser dito sobre a recursão. Mas para entender melhor o significado da recursão, você pode recorrer à semântica da linguagem - no exemplo discutido acima, esta é a linguagem dos números inteiros decimais assinados. Vamos considerar seu significado.
Definição de gramática. Forma de ekusa-maura “ZO/
Se você tentar definir o que é um número, poderá começar com o fato de que qualquer número em si é um número. Além disso, você pode notar que quaisquer dois dígitos também são um número, depois três dígitos, etc. Se você construir a definição de um número usando este método, ele nunca será concluído (em matemática, a capacidade de dígito de um número não é limitado por nada). Porém, você pode notar que cada vez que geramos um novo número, simplesmente adicionamos uma unidade à direita (já que estamos acostumados a escrever da esquerda para a direita) à série de números já escrita. E esta série de números, começando com um dígito, também é um número. Então a definição do conceito “número” pode ser construída desta forma: “um número é qualquer dígito, ou outro número ao qual qualquer dígito é adicionado à direita”. Isto é precisamente o que constitui a base das regras das gramáticas G e G" e se reflete na segunda linha das regras nas regras<чс>-><цифра> [ <чс><цифра>e T->F | TF. Outras regras nessas gramáticas permitem adicionar um sinal a um número (primeira linha de regras) e definir o conceito de “dígito” (terceira linha de regras). Eles são elementares e não requerem explicação.
O princípio da recursão (às vezes chamado de “princípio da iteração”, que não muda a essência) é um conceito importante na ideia de gramáticas formais. De uma forma ou de outra, explícita ou implicitamente, a recursão está sempre presente nas gramáticas de qualquer linguagem de programação real. É justamente isso que permite construir um número infinito de cadeias linguísticas, e é impossível falar sobre sua geração sem compreender o princípio da recursão. Normalmente na gramática de uma língua real? a programação contém não uma, mas todo um conjunto de regras construídas usando recursão.
Outras maneiras de definir gramáticas
A forma Backus-Naur é conveniente do ponto de vista formal, mas nem sempre fácil de entender, de escrever gramáticas formais. Definições recursivas são boas para análise formal de cadeias de linguagem, mas não são convenientes do ponto de vista humano. Por exemplo, quais são as regras<чс>-><цифра> | <чс><цифра>refletem a capacidade de construir um número adicionando qualquer número de dígitos à direita, começando com um, o que não é óbvio e requer explicação adicional.
Mas ao criar uma linguagem de programação, é importante que sua gramática seja compreendida não apenas por quem irá criar compiladores para esta linguagem, mas também pelos usuários da linguagem - futuros desenvolvedores de programas. Portanto, existem outras formas de descrever as regras das gramáticas formais que visam uma maior compreensão humana.
Escrevendo regras gramaticais
usando metacaracteres
Escrever regras gramaticais usando metacaracteres pressupõe que a sequência de regras gramaticais pode conter caracteres especiais - meta-
358 Capítulo 9. Linguagens formais e gramáticas
Símbolos – que têm um significado especial e são interpretados de maneira especial. Os metacaracteres mais comumente usados são () (parênteses), (colchetes), () (chaves), “,” (vírgula) e “” (aspas). Esses metacaracteres têm o seguinte significado:
□ parênteses significam que de todas as cadeias listadas dentro deles
caracteres em um determinado local da regra gramatical só pode haver um ce
botão;
□ colchetes significam que a cadeia especificada neles pode ocorrer
regras gramaticais podem ou não ocorrer em um determinado lugar (isto é, elas podem
pode estar presente uma vez ou nunca);
□ chaves significam que a string especificada dentro delas pode não ocorrer
regras gramaticais aparecem em um determinado lugar mais de uma vez, ocorrem uma vez
uma vez ou quantas vezes desejar;
□ uma vírgula é usada para separar sequências de caracteres dentro de círculos
colchetes;
□ aspas são usadas nos casos em que um dos metacaracteres é necessário
incluir na cadeia da maneira usual - isto é, quando um dos colchetes ou atrás
o quinto deve estar presente na cadeia de caracteres do idioma (se a própria citação
precisa ser incluído em uma cadeia de caracteres, então deve ser repetido duas vezes - isso
o princípio é familiar aos desenvolvedores de programas).
Esta é a aparência das regras da gramática G discutidas acima se escritas usando metacaracteres:
<число> -» [(+.-)]<цифра>{<цифра>}
<цифра> ->0|1|2|3|4|5|6|7|8|9
A segunda linha das regras dispensa comentários, e a primeira regra diz assim: “um número é uma cadeia de caracteres, que pode começar com os símbolos + ou -, deve então conter um dígito, que pode ser seguido por um sequência de qualquer número de dígitos.” Ao contrário da forma Backus-Naur, na forma de escrita usando metassímbolos, como você pode ver, em primeiro lugar, um símbolo obscuro não terminal é removido da gramática<чс>e, em segundo lugar, conseguimos eliminar completamente a recursão. A gramática eventualmente ficou mais clara.
A forma de escrever regras usando metassímbolos é uma maneira conveniente e compreensível de representar as regras das gramáticas. Em muitos casos, permite que você se livre completamente da recursão, substituindo-a pelo símbolo de iteração () (chaves). Como ficará claro em material posterior, esta forma é mais comum para um dos tipos de gramáticas - gramáticas regulares.
Gravando regras gramaticais em formato gráfico
Ao escrever regras em forma gráfica, toda a gramática é apresentada na forma de um conjunto de diagramas especialmente construídos. Essa forma foi proposta na descrição da gramática da língua Pascal e depois se difundiu na literatura. Não está disponível para todos os tipos de gramáticas, mas apenas
Definição de gramática. Formulário Backus-Naur 359
Para tipos livres de contexto e regulares, mas isso é suficiente para que possa ser usado para descrever gramáticas de linguagens de programação conhecidas.
Nesta forma de notação, cada símbolo não terminal da gramática corresponde a um diagrama construído na forma de um grafo direcionado. O gráfico possui os seguintes tipos de vértices:
□ ponto de entrada (não indicado de forma alguma no diagrama, simplesmente começa a partir daí)
arco de entrada do gráfico);
□ símbolo não terminal (denotado por um retângulo no diagrama, no qual
qual a designação do símbolo é inserida);
□ uma cadeia de símbolos terminais (no diagrama indicado por um oval, um círculo
ou um retângulo com bordas arredondadas, dentro do qual está inscrito
botão);
□ ponto nodal (no diagrama indicado por um ponto em negrito ou sombreado
círculo);
□ ponto de saída (não marcado de forma alguma, o arco de saída do gráfico simplesmente entra nele).
Cada diagrama possui apenas um ponto de entrada e um ponto de saída, mas qualquer número de vértices dos outros três tipos. Os vértices são conectados entre si por arcos gráficos direcionados (linhas com setas). Os arcos só podem sair do ponto de entrada e entrar apenas no ponto de entrada. Os vértices restantes do arco podem entrar e sair (em uma gramática construída corretamente, cada vértice deve ter pelo menos uma entrada e pelo menos uma saída).
Para construir uma cadeia de símbolos correspondente a qualquer símbolo gramatical não terminal, é necessário considerar o diagrama desse símbolo. Então, começando do ponto de entrada, você precisa se mover ao longo dos arcos do gráfico do diagrama através de quaisquer vértices até o ponto de saída. Neste caso, passando por um vértice designado por um símbolo não terminal, este símbolo deverá ser colocado na cadeia resultante. Ao passar por um vértice indicado por uma cadeia de símbolos terminais, esses símbolos também devem ser colocados na cadeia resultante. Ao passar pelos pontos nodais do diagrama, nenhuma ação precisa ser executada na cadeia resultante. Dependendo do possível caminho de movimento, você pode passar por qualquer vértice do gráfico do diagrama uma vez, não uma vez ou quantas vezes quiser. Assim que chegarmos ao ponto de saída do diagrama, a construção da cadeia resultante estará concluída.
A cadeia resultante, por sua vez, pode conter símbolos não terminais. Para substituí-los por sequências de símbolos de terminal, você precisa considerar novamente os diagramas correspondentes. E assim por diante até que apenas os caracteres terminais permaneçam na cadeia. Obviamente, para construir uma cadeia de símbolos de uma determinada língua, deve-se começar a consideração com o Diagrama do símbolo da gramática alvo.
Esta é uma forma conveniente de descrever as regras das gramáticas, operando com imagens e, portanto, focada exclusivamente nas pessoas. Mesmo uma simples apresentação dos seus princípios básicos revelou-se aqui bastante complicada, enquanto a essência
Capítulo 9. Linguagens formais e gramáticas
O método é bastante simples. Isto pode ser facilmente visto se você olhar a descrição do conceito “número” da gramática G usando os diagramas da Fig. 9.1.
Arroz. 9.1. Representação gráfica da gramática dos inteiros decimais com sinal: no topo - para o conceito de “número”; abaixo - para o conceito de “dígito”
Conforme mencionado acima, este método é utilizado principalmente na literatura na apresentação de gramáticas de linguagens de programação. É conveniente para usuários - desenvolvedores de programas, mas ainda não tem aplicação prática em compiladores.
Classificação de línguas e gramáticas
Vários tipos de gramáticas já foram mencionados acima, mas não foi indicado como e com que base elas são divididas em tipos. Para uma pessoa, as linguagens podem ser simples ou complexas, mas esta é uma opinião puramente subjetiva, que muitas vezes depende da personalidade da pessoa.
Para os compiladores, as linguagens também podem ser divididas em simples e complexas, mas neste caso existem critérios rígidos para esta divisão. Como será mostrado a seguir, depende do tipo ao qual pertence uma determinada linguagem de programação.
Rovania, depende da complexidade do reconhecedor para esta linguagem. Quanto mais complexa a linguagem, maiores são os custos computacionais do compilador para analisar as cadeias do programa fonte escrito nesta linguagem e, portanto, mais complexos são o próprio compilador e sua estrutura. Para alguns tipos de linguagens, é em princípio impossível construir um compilador que analise textos fonte nessas linguagens em um tempo aceitável com base em recursos computacionais limitados (é por isso que ainda é impossível criar programas em linguagens naturais, por por exemplo, em russo ou inglês).
Classificação de gramáticas.
Propriedade LL(k) impõe grandes restrições à gramática. Às vezes é possível transformar uma gramática de modo que a gramática resultante tenha propriedade LL(1) . Tal transformação nem sempre é bem sucedida, mas se for possível obter uma gramática LL(1), então para construir um analisador você pode usar o método descendente recursivo sem retrocesso.
Suponha que precisemos construir um analisador para uma linguagem gerada pela seguinte gramática:
E → E + T | E – T | T
T → T * F | T/F | F
F → número | (E)
Vários terminais PRIMEIRO(T) também pertencem ao conjunto PRIMEIRO(E+T), portanto, é impossível determinar inequivocamente a sequência de chamadas de procedimento que devem ser executadas ao analisar a cadeia de entrada. O problema é que o não-terminal E ocorre na primeira posição do lado direito da regra, cujo lado esquerdo também é E. Em tal situação, o não-terminal Eé chamado de recursivo diretamente à esquerda.
Não terminal A Gramáticas KS G chamado recursivo à esquerda , se houver uma conclusão na gramática A =>* Ah.
Uma gramática que possui pelo menos uma regra recursiva à esquerda não pode ser LL(1)-gramática.
Por outro lado, sabe-se que toda linguagem CS é definida por pelo menos uma gramática recursiva não-esquerda.
Algoritmo para eliminar a recursividade à esquerda
Deixar G = (N, T, P, S)– Gramática e regra KS A→Ah 1 | Ah 2 | ... | Ah n | v 1 | v 2 | ... | v eu representa todas as regras de P contendo A no lado esquerdo, e nenhuma das correntes v eu não começa com um não-terminal A.
Vamos adicionar ao conjunto N outro não-terminal A" e substituir as regras que contêm A no lado esquerdo, para o seguinte:
UMA → v 1 | v 2 | ... | v eu | v 1 A' | v 2 Um' | ... | v eu A"
UMA' → w 1 | c 2 | ... | c n | c 1 Um' | c 2 Um' | ...| c n A"
Pode-se provar que a gramática resultante é equivalente à original.
Como resultado da aplicação desta transformação à gramática acima que descreve expressões aritméticas, obtemos a seguinte gramática:
E → T | T.E."
E" → + T | + T.E."
T → F | F. T."
T"→ * F | * F. T."
F → (E) | número
É fácil mostrar que a gramática resultante possui a propriedade LL(1).
Outro problema semelhante ocorre quando duas regras para o mesmo não-terminal começam com os mesmos caracteres.
Por exemplo,
S → se E então S, senão S
S → se E então S
Neste caso, adicionaremos outro não-terminal que corresponderá aos diferentes finais destas regras. Obtemos as seguintes regras:
S → se E então S S’
S" →
S"→ outro S
Para a gramática resultante, o método descendente recursivo pode ser implementado.
9.1.4. Descida recursiva com retornos.
Para poder aplicar o método da descida recursiva é necessário 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 transformar a gramática em uma forma na qual os conjuntos PRIMEIRO não se cruzam, o que é um processo complexo, então na prática uma técnica chamada descida recursiva com retornos .
Para isso, o analisador léxico é representado como um objeto que, além dos métodos tradicionais Varredura, próximo etc., também existe um construtor de cópia. Então, em todas as situações em que possa surgir ambiguidade, antes de iniciar a análise, você deve lembrar o estado atual do analisador lexical (ou seja, fazer uma cópia do analisador lexical) e continuar a análise do texto, considerando que estamos lidando com o primeiro dos as construções possíveis nesta situação. Se esta opção de análise falhar, será necessário restaurar o estado do analisador léxico e tentar analisar o mesmo fragmento novamente usando a próxima opção gramatical, etc. Se todas as opções de análise falharem, um erro será relatado.
Este método de análise é potencialmente mais lento que a descida recursiva sem retrocesso, mas neste caso é possível preservar a gramática na sua forma original e poupar o esforço do programador.





 As células neurogliais desempenham um papel")